The new .NET 4.5 feature every XAML developer will love
If you develop using XAML and you are using .NET 4.5 (i.e. WPF or Windows 8) then there is a feature that will make you smile a bit, CallerMemberName. XAML developers often implement INotifyPropertyChanged to enable updating of data bound fields. If are smart, you often wrap the raising of the event into a simple method you can call, for example:
public void RaisePropertyChange(string propertyName)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}
This leads to code that looks like this:
private int ticks;
public int Ticks
{
get { return ticks; }
set
{
if (ticks != value)
{
ticks = value;
RaisePropertyChange("Ticks");
}
}
}
There are some problems with this
- Refactoring – rename the Ticks property and even if you use the VS refactoring tool it won’t find the string in the method call.
- Magic strings – It is just a string so there is nothing to make sure that you spelt Ticks in the string the same as Ticks in the property name.
- Copy & Paste – If you copy & paste another property, you must remember to rename this string too.
The solution: CallerMemberName
.NET 4.5 includes a new parameter attribute called System.Runtime.CompilerServices.CallerMemberName which will automatically place the name of the calling member (i.e. method or property) into the parameter. This enables us to change the method signature to:
public void RaisePropertyChange([CallerMemberName] string propertyName = "")
Note: The attribute in front of the property & note we have also given it a default value – when using this attribute your parameter must have a default value.
Now we can change the calling definition to
private int ticks;
public int Ticks
{
get { return ticks; }
set
{
if (ticks != value)
{
ticks = value;
RaisePropertyChange();
}
}
}
Now we have solved all the problems with the string in the method call! Go and enjoy!
Below is a file with a sample application to get you started (everything is in MainPage.xaml.cs).
Rapid Business Development: LightSwitch vs. Dynamics CRM vs. SharePoint vs. ASP.NET MVC
Over a year ago I wrote a post where I compared four technologies that can be used to build business applications rapidly. The original post was inspired by how similar a number of products have become over the last few years and more importantly how Visual Studio LightSwitch, which is a specialized rapid business tool development platform built on top of Visual Studio, is going to affecting the development eco-system. That post was written in the LightSwitch Beta 2 timeframe and the world has changed a lot since then – LightSwitch has shipped, not once but TWICE! So it is about time it got a refresh.
As with the previous post I am going to compare LightSwitch against Dynamics CRM, SharePoint & ASP.NET MVC Scaffolding. If you are not aware of these different products see my older post for a brief overview of them.
I think the differences between these four are very interesting and while each has its strong & weak points, this should definitely not be looked at as a pick one only post. There are many scenarios where you want to combine them for even better experiences.
To be clear that ASP.NET MVC is greater than ASP.NET MVC Scaffolding – you can do almost anything with MVC, however for this article we are looking at the concept of rapid development and comparing MVC with MVC scaffolding, scaffolding will give you a more rapid development with trade-offs. An example of this is databases supported, where MVC supports anything .NET does but scaffolding is a subset of databases.
I have broken down the issues into twenty two (!) aspects (key points we can compare them against each other) which are grouped into six scenarios to make it easier to digest. Each scenario starts with a list of the aspects and a brief description followed by a comparison table of those aspects. All the aspects are numbered so you can easily scan the table & if there are notes available the information will give you the relevant note numbers (see image below for more info).

Starting
- Ready to go out of the box: Once installed, can it do anything? Seems silly, but quick turnaround at the start, even if actual development is longer is important as it helps with prototyping, shows some rapid development and hints at how hard it is to learn (for me at least, if it does something I find I can experiment and learn quickly). Important to note, we are not looking at making it align with your company needs here, we just want it to do something. Eating CPU cycles & RAM is not something either.
- Northwind Style Sample development costs: This aspect looks further than the above aspect and looks at how much more would it take to get it tailored for a company, like the fictional Northwind, to have a XRM type system as it can be done across all four. Fewer $ signs means less time and/or resources for the functionality.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 Ready to go out of the box | Medium (see note 1) | Fastest (see note 2) | Fast | Slowest (see note 1) |
|
| Aspect 2 Northwind Style Sample development costs | $ (see note 2) | $$ | $$ | $$$ (see note 1) |
|
Finishing
- Cost for on-premise deployments: This looks at the money cost for licensing to get the solution up and running on premise (i.e. in your company). Licensing is, of course, flexible and this will vary based on who you are – so this is not indicative for all. It does not include such things as server hardware or common costs, for example operating system licensing.
- Deployment Complexity: Getting a solution up and running shouldn’t be difficult for an organization and a lot of time can be lost (and costs incurred) changing, upgrading and troubleshooting systems that do not want to be deployed.
- Deployment Documentation: When it happens that you need to deploy, having a wealth of documentation (be that video’s, best practice guides, troubleshooting material) is vital and plays a large part in getting a solution up that works every time.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 Cost for on premise deployments | $$ Visual Studio licenses. No per user costs. (see note 2) | $ to $$$ Cost per user & cost per server. Visual Studio only if you are doing integrations or custom workflows. (see note 1) | $$$$ to $$$$+ Cost per user & cost per server. Visual Studio licenses for any serious work. | $$ Visual Studio licenses. No per user costs. (see note 2) |
|
| Aspect 2 Deployment Complexity | Easy (see notes 1 & 2) | Hard (see note 1) | Hardest (see note 1) | Easiest (see notes 1 & 3) |
|
| Aspect 3 Deployment Documentation | Yes (see note 2) | Yes (see note 2) | Yes (see note 2) | Yes (see note 1 & 2) |
|
User Experience
- Front End Technology: A good looking, feature rich UI can seriously ease adoption, and what we are looking at here is the richness level of technology used for the out of the box front end user interface.
- How good the standard UI looks: Completely subjective and really this is based on what I think looks best.
- Flexibility of out of box front end: In this aspect we are concerned about how easy it is to adjust and tweak the out of the box front end.
- Themability: Corporate branding is massive business and making sure the application out of the box looks like it is part of your business is important. It is important to note that both CRM & SharePoint can have custom front ends built which enable this scenario, but that requires extra development, and we are focusing on the out of the box options here and assuming you have the theme built already.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 Front End Technology | Silverlight. Supports out of browser (desktop) & in browser (see note 1) | Web Just ASP.NET | Web ASP.NET under the covers with sprinklings of Silverlight | ASP.NET (see note 2) |
|
| Aspect 2 How good the standard UI looks (very subjective) | Medium (see note 2) | Medium (see note 3) | Today: Very Low Future: Medium (see note 1) | Depends on your web designer (see note 3) | This is the most subjective aspect:
|
| Aspect 3 Flexibility of UI development in the tool | High (see note 1) | Medium (see note 2) | Medium (see note 2) | High (see note 1) |
|
| Aspect 4 Themability | Today: High Future: Highest (see notes 1, 2 & 3) | Low (see note 4) | Medium (see note 3) | Highest (see note 1) |
|
Extensibility
- API for integration: In the short term having an API means it is easy to get data into your new solution, in the medium term it means more ways to sync data and mash up your systems and in the long term it gives you a way to get your data out. It is vital to have an API.
- Marketplace: Apple kicked the idea of having an AppStore into reality for many of us and now having a marketplace to get extensions, customisations or themes is an important aspect. I am ignoring public sites, like Codeplex for example, and only focusing on an official marketplaces. Galleries are just marketplaces with no vetting, which means they are bigger but the quality bar is not guaranteed.
- Additional Authentication Options: Only your employees or customers (which may be everyone if you are lucky enough) should access your solutions. What do we get out of the box to limit access to the system? All four systems support Windows & Forms based authentication so I am only listing other options which are available.
- Permission Structure (Authorisation): Being able to control what parts of a solution you can access, once you have logged in is also vital and having a lot of flexibility in this space is also important as very seldom will one structure work for everyone.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 API for integration | Yes (see note 2) | Yes (see note 3) | Yes - at least 5 of them. (see note 3) | Yes (see note 1) |
|
| Aspect 2 Marketplace | Gallery available (see note 3) | Yes (see note 1) | Nope (see note 2) | Gallery available (see note 3) |
|
| Aspect 3 Additional Authentication Options | Anonymous, Custom, Windows Authentication (AD) & Forms based. (see notes) | Claims based authentication via STS | Anonymous and more available through custom development (e.g. Windows Live). Claims based authentication (custom development required). | Anonymous and more available through custom development (e.g. Windows Live). Claims based authentication (custom development required). | LS makes use of ASP.NET Authentication Provider so it fits nicely into the technologies developers already know. |
| Aspect 4 Permission Structure (Authorisation) | Very complete model for permissions. Minor coding required. (see note 2) | Fantastic out of the box option, plus plenty of extensibility if needed. (see note 3) | Good structure with many levels of customisation. Out of the box is very simple. (see note 3) | Basic support for it but can be extended through development. A lot of XML work though may be needed. (see note 1) |
|
Information Worker Features
- Offline support: Being able to work when you are not in the office is a vital need for many people. So how do these platforms enable that scenario? In theory it is always possible to build this, so we are just looking at the out of box offering. This scenario is focused on offline with a laptop, not a tablet or mobile phone.
- Easily Import Data: How do we get information into the solution, besides the API? Does the product make this easy with out of the box tooling?
- Printing: Despite the promise of a paperless office, it still is not the case and being able to print is important, even if it is just to XPS or PDF for invoicing.
- Office Integration: Integration into Microsoft Office products (i.e. Word, Excel, Outlook, PowerPoint, Access, Publisher, and InfoPath & OneNote) means that your IW’s will be able to work in the tools that they are comfortable with, easing adoption and productivity.
- Mobile Device Support: Information workers are increasingly mobile and having good mobile device support is a critical feature. When I look at this I am not just thinking about the simple, does it support it but also how well it supports mobile devices.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 Offline support | No (see notes) | Yes (see notes) | Yes (see notes) | No (see notes) | Being able to work offline is important if you are a roaming user. LS & MVC offer nothing in this space while CRM & SP both offer offline via Outlook. |
| Aspect 2 Easily Import Data (out of the box) | Nope (see notes) | Yes, from CVS. (see notes) | Yes. Multiple options. (see notes) | Nope (see notes) | In all cases there are tools and other ways to import data (for example LS has the http://officeintegration.codeplex.com extensions) but CRM & SP have an out of the box options. |
| Aspect 3 Printing (out of the box) | Nope (see note 1) | Yes (see note 4) | Yes – Poor (see note 3) | Browser Level (see notes 1 & 2) |
|
| Aspect 4 Office Integration | Low One way export to Excel in out of browser mode only. Others can be custom developed or use the OfficeIntegration extensions (http://officeintegration.codeplex.com) | Medium One way to Excel. Mail merge with Word & Outlook. Deep integration with Outlook is available too. | High Only Publisher doesn’t have some integration with SharePoint. Every other Office product does, some like Excel are one way while others like Access are two way. SP internally has features that understand Office files too, for example PowerPoint Libraries show thumbnails. | None Can be custom developed. | |
| Aspect 5 Mobile Device Support | Today: Limited Future: Fantastic (see note 1) | Good (see note 2) | Okay (see note 3) | Fantastic (see note 4) |
|
Other
- Databases Supported: Where the data can come from for your application is a critical piece of the puzzle because it means the difference between building ETL solutions to handle moving it around if the source is supported or having it just work.
- Minimum Skills for Tailoring: Tailoring is what I refer to when I think of customisation of a system, without the need for a programming language. At some point you will need a developer but how far away that is and what can be done by a analyst or super user early on is important from a time to solution and cost perspective. Lower is better here.
- Can run in the cloud? If you not thinking about how you can leverage the cloud, then you are not thinking. Making sure the solutions can cater for the cloud is an important consideration. All four solutions can run in the cloud but how do they run is also important
- ALM Experience: How does this tool work with a full ALM experience? Can I unit test it easily? Will it go into source control easily and what happens when multiple developers are updating the same files? How about build server and development tool integration? All important questions in understanding a complete picture of that these tools cost or what you sacrifice with some of them.
- Requires Silverlight: Despite decent market penetration and ease of deployment in corporate scenarios, the requirement for Silverlight can be a deterrent to business, especially those where the CEO uses an iPad. This is not answered in the table as only LightSwitch requires Silverlight today (in the future it will support HTML). CRM has no dependencies, SharePoint has a fall back mode and if you used Silverlight with MVC it would be possible to have a fallback mode, provided you developed it.
- Data performance: This is also not in the table since it only applies to LightSwitch. For CRM, MVC & SharePoint I assume your front end (web) is always close enough, for example the same LAN, to the database but in LightSwitch you can really separate them. Here it is important to note LightSwitch is NOT great with data performance between backend & frontend out of the box, however with careful tailoring of data sources & screens you can greatly improve it. It sends massive amounts of data around. In my view it really does not feel optimised for low bandwidth WAN scenarios.
| LightSwitch (LS) | Dynamics CRM | SharePoint 2010 (SP) | ASP.NET MVC | My Notes | |
| Aspect 1 Databases Supported | Out of the box:
| SQL Server | SQL Server normally. With advanced skills can use external data sources with BDC. External content types can also be used in place of BDC with a lower skill set (power users) but at a smaller feature set supported. | For scaffolding anything supported by LinqToSQL or Entity Framework. | |
| Aspect 2 Minimum Skills For Tailoring | Low (see note 3) | Lowest (see notes 1 & 3) | Low (see note 1) | Highest (see note 2) |
|
| Aspect 3 Can run in the cloud? | Platform as a service using SQL Azure for database & compute instances for front end. Also supports the new Azure Websites options. | Software as a service: Can get it from Microsoft & Partners at a cost per user per month. | Software as a service: Can get it from Microsoft (Office 365) & Partners at a cost per user per month. | Platform as a service using SQL Azure for database & compute instances for front end. Also supports the new Azure Websites options. | |
| Aspect 4 ALM Experience | Medium (see note 3) | Low (see note 3) | High (see note 2) | Highest (see note 1) |
|
Finally
A post like this is not possible to do without some amazing people providing feedback and I want to say a special thanks to:
SharePoint and protocol-relative URL's
Introduction to protocol-relative URL’s
Recently I learnt an amazing new trick, the protocol-relative URL where the scheme of a URL (the http bit) can be dropped and your browser will use the same scheme as the page’s URL uses. This is very useful for when you have a website on http & https. For example you can set a image URL to be
//demo.com/horse.png and if you browse to http://www.demo.com then it will load the image from http://demo.com/horse.png, but if you got to https://www.demo.com then it will load the image from https://demo.com/horse.png – and this works with CSS & JavaScript too!
This is not some odd browser trick, this is in the standard for how URL’s work!
To be clear this is similar, but not the exact same as absolute & relative URLs.
SharePoint
SharePoint (and for this post, this has only been checked with 2010 so your mileage may vary on newer/older versions) does not follow this standard and actually breaks protocol-relative URL’s in two ways.
Front End
If you are working on the SharePoint UI and putting content in a content editor web part or an text column in a list and you edit the HTML and put in a protocol-relative URL SharePoint and hit save SharePoint will “fix” it by putting the current scheme in for you! So no matter what you do, on the front end you are completely stuffed.
Example
You put in <img src=”//sharepoint/horse.png”/> SharePoint will change it to <img src=”http://sharepoint/horse.png”/> (assuming your page is on a http scheme).
Back End
The other scenario is you are working with the SharePoint web services, for example the list service, and setting the HTML that way – SharePoint once again will try and “fix” things. Interesting it does something completely different to the front end. I guess the front end uses JavaScript and the back end uses some other code. It removes the attribute completely from the HTML.
Example
You put in <img src=”//sharepoint/horse.png”/> SharePoint will change it to <img /> – yip the src attribute is gone.
Mythbusters: You should use an Array because it is the only collection that can be serialised
Another in my theme of investigating claims that to me sound wrong, this time that arrays should be chosen over other collections because only arrays can be serialised (or put differently, no other collection can be serialised).
For this I am assuming serialised means to XML, and it also means serialised easily. In theory anything can serialised as it just a concept, which is why I am assuming easily – i.e. no custom code outside of invoking built in framework serialisation.
Serialisation with XmlSerialiser
private static string Serialise<T>(T o)
{
var serializer = new XmlSerializer(typeof(T));
var memoryStream = new MemoryStream();
serializer.Serialize(memoryStream, o);
memoryStream.Position = 0;
using (var reader = new StreamReader(memoryStream))
{
return reader.ReadToEnd();
}
}
With the above code you can pass in an array and spits out XML. It also works perfectly with ArrayList & List<T>. This does fail with LinkedList<T> and Dictionary<T,K> which is annoying.
Serialisation with DataContractSerializer
The myth I think comes from lack of knowledge of what is in the .NET Framework, in this case thinking there is one way to serialise something when the framework ships with many of them. So lets use DataContractSerializer this time and see:
private static string Serialise2<T>(T o)
{
var serializer = new DataContractSerializer(typeof(T));
var memoryStream = new MemoryStream();
serializer.WriteObject(memoryStream, o);
memoryStream.Position = 0;
using (var reader = new StreamReader(memoryStream))
{
return reader.ReadToEnd();
}
}
Using this Array, ArrayList, List<T>, LinkedList<T> & Dictionary<T,K> are all serialised!
Myth Outcome
BUSTED! There is a simple way to serialise the collection classes in the framework – so array’s are not the only thing that can be serialised!
MythBusters: Arrays versus Collections
Code now available at https://github.com/rmaclean/ArrayFighter. If you wish to suggest a flaw or make a suggestion to improve it please create a pull request OR give me a detailed comment explaining what is needed, why it will help/hinder etc... ideally with links.
The myths I want to tackle are:
- Arrays are not collections
- Arrays are faster than collections
These are two statements I have heard recently and I initially felt are wrong, so to check I myself I decided to research this myth. I am assuming when people say collections they mean classes in System.Collections or System.Collections.Generics.
Arrays are not collections
In computer science, an array type is a data type that is meant to describe a collection of elements
Source: http://en.wikipedia.org/wiki/Array_data_type
So we have established that they are collections but how to they compare to say .NET collection classes like List<T>, ArrayList & LinkedList<T>?
List<T>
Official Documentation: http://msdn.microsoft.com/en-us/library/6sh2ey19.aspx
What it implements
The first aspect is what interfaces are implemented in each, and you can see below both implement the same interfaces that deal with collections and lists. Note that since List<T> is generic we have both generic & non-generic interfaces.
- Array implement: ICloneable, IList, ICollection, IEnumerable, IStructuralComparable, IStructuralEquatable
- List<T> implement: IList<T>, ICollection<T>, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T>, IEnumerable<T>, IEnumerable
Where is the data?
Where does List>T? store data? In an internal field: _items which is just an array of T.
So List<T> is just an array? Yup! So how does it handle inserting new items? It increases the array size when needed by creating a new array and copying the pointers to the items into it.
Complexity of the operations
- Add: O(1) operation. If the capacity needs to be increased to accommodate the new element, this method becomes an O(n) operation, where n is Count.
- Insert: O(n) – where n is count
- Remove: O(n) – where n is count
ArrayList
Official Documentation: http://msdn.microsoft.com/en-us/library/system.collections.arraylist.aspx
Let me warn you about ArrayList, if you are using .NET 2.0 or higher and you are using this class, I have the full right to smack you across the face with a glove. There is NO REASON TO USE THIS ANYMORE! Use List<T> instead, it is faster & safer.
What it implements
The first aspect is what interfaces are implemented in each, and you can see below both implement the same interfaces that deal with collections and lists.
- Array implement: ICloneable, IList, ICollection, IEnumerable, IStructuralComparable, IStructuralEquatable
- ArrayList implement: IList, ICollection, IEnumerable, ICloneable
Where is the data?
Where does ArrayList store data? In an internal field: _items which is just an object[].
So ArrayList is just an array? Yup! So how does it handle inserting new items? It increases the array size when needed by creating a new array and copying the pointers to the items into it.
Complexity of the operations
- Add: O(1) operation. If the capacity needs to be increased to accommodate the new element, this method becomes an O(n) operation, where n is Count.
- Insert: O(n) – where n is count
- Remove: O(n) – where n is count
Did you copy and paste List<T> for ArrayList?
Yip – because they are virtually the same, in fact the only core difference is that the internal storage is object[] versus T[]. That has side effects, like the Add methods taking in T versus object but that is it!
LinkedList<T>
Official Documentation: http://msdn.microsoft.com/en-us/library/he2s3bh7.aspx
So now we are onto something really different. An Array (and as we have seen ArrayList & List<T>) assign a continuous block of memory (number of items * item size) and then put the items in there are the correct offset.
This has the benefit for reading, for example if I need item 6, all I do is work out 6 * item size + start of array in memory and boom I am at the item. However, the problem is when I run out of space – List<T> & ArrayList solve this by making new bigger arrays! The cost of this is very high indeed (two arrays, having to copy all the items from one array to another, cleanup of the first array).
LinkedList is different, it knows about the first item in the collection, and that item has a property to the next item in the collection and so on. This means that I can add infinitely and never have issues as all I do is get the last item, and set it’s property to point to the my new item. Inserts are also way faster compared to arrays – rather than having to move all items down (as Arrays must) we just need to adjust the properties of the item before & the item I am inserting. So it is awesome? Nope – Reading is way slower.
If I need to get to item 6? I need to go to item 1, then item 2 and so on – moving along the entire way. It is slow, VERY much so. However moving backwards may be faster! This is because the node has not only a property that shows the next item but also a property that shows the previous item. So if I need to move one back it is very quick and easy, compare to arrays where I need to go back to the start and apply some math. Performance of moving backwards will really depend on how many steps backwards & the size, so in some cases array may still be faster.
What it implements
The first aspect is what interfaces are implemented in each, and you can see below both implement the same interfaces that deal with collections but not lists. So it is a collection, in the .NET sense, but not a list. It also contains the generic and non-generic versions.
- Array implement: ICloneable, IList, ICollection, IEnumerable, IStructuralComparable, IStructuralEquatable
- LinkedList<T> implement: ICollection<T>, IEnumerable<T>, ICollection, IEnumerable, ISerializable, IDeserializationCallback
Where is the data?
LinkedList<T> stores the first item in the list in a field called head which is of type LinkedListNode<T> which points to the first node in the collection. That is it, thee rest of the items in the collection are just linked to the head.
Complexity of the operations
- AddFirst: O(1) operation.
- AddLast: O(1) operation.
- AddBefore: O(1) operation.
- AddAfter: O(1) operation.
- Remove: O(n) – where n is count
- RemoveFirst: O(1) operation
- RemoveLast: O(1) operation
Myth Outcome?
BUSTED! Arrays are collections, in both CS & .NET definitions.
Arrays are faster than collections
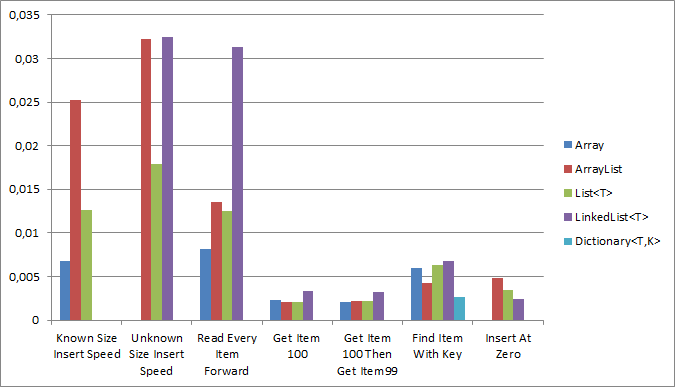 So let’s see if they are with some micro-benchmarks & the code, if you want to dispute, is below.
So let’s see if they are with some micro-benchmarks & the code, if you want to dispute, is below.
I ran 6 tests on Array, ArrayList, List<T>, LinkedList<T> & Dictionary<T,K>
The tests were:
- If we know we have 1000 items ahead of time – optimise and insert 1000 ints.
- Insert 1000 ints, but do not preallocate any space more than 4.
- Read every item in an collection of 100 and validate it.
- Get the 100th item and validate it.
- Get the 100th item, and then the 99th item and validate it.
- Get an item based on a key
- Insert an item at position 0.
Results
9 July 2012: As I added a new test I re-tested everything (so numbers & chart has been updated) – however the winner did not change on the tests.
Inserting into a known size?
Winner: Array
No surprise here.
LinkedList disqualified because you can’t preallocate.
Disqualified
- Dictionary: Needs a key – we only have values in this test.
Inserting into an unknown size?
Winner: List<T>.
Interesting is that I would’ve assumed LinkedList to be faster & ArrayList to be closer to List<T>.
In hindsight it makes sense that LinkedList is slower – it needs to find the last item first as we we are adding at the end.
Disqualified
- Array: Disqualified since it can’t magically expand like the others.
- Dictionary: Needs a key – we only have values in this test.
Read every item?
Winner: Array
Disqualified
- Dictionary: Needs a key – we only have values in this test.
Get Item 100?
Winner: ArrayList.
Interesting here since I would’ve guessed Array but these are all so close it likely is just background noise interfering.
Disqualified
- Dictionary: Needs a key – we only have values in this test.
Get Item 100 & 99
Winner: Array
This test was designed for LinkedList, so very surprised it didn’t win but these are all so close it likely is just background noise interfering
No surprise – it is perfect for this situation.
Disqualified
- Dictionary: Needs a key – we only have values in this test.
Find with a key
Winner: Dictionary.
No surprise – it is perfect for this situation.
Insert At Zero
Winner: LinkedList<T>.
No surprise – it is perfect for this situation.
Disqualified
- Array: No way to insert at zero.
- Dictionary: Needs a key – we only have values in this test.
Raw Numbers
| Test | Array | ArrayList | List<T> | LinkedList<T> | Dictionary<T,K> |
| Known Size Insert Speed | 0,0067952 | 0,0251845 | 0,0125625 | ||
| Unknown Size Insert Speed | 0,0322676 | 0,0178365 | 0,0324339 | ||
| Read Every Item Forward | 0,0081916 | 0,0135402 | 0,0124702 | 0,03132 | |
| Get Item 100 | 0,0023351 | 0,0021007 | 0,0021014 | 0,0033034 | |
| Get Item 100 Then Get Item99 | 0,0020214 | 0,0021889 | 0,002163 | 0,0032026 | |
| Find Item With Key | 0,0059856 | 0,0042258 | 0,0063673 | 0,0067397 | 0,0026851 |
| Insert At Zero | 0,0047753 | 0,0034568 | 0,0024224 |
Myth Outcome?
BUSTED! Arrays are fast, taking half the awards for speed, but they are not universally the fastest (depends on situation) and also the other options are so close that performance is likely not the issue when considering which structure to choose.
Lightswitch & the HTML Client - what does this mean?
Lightswitch Recap
For you to understand the rest of this post it is vital you have a high level understanding of Lightswitch and how it works. Lightswitch is a RAPID development platform from Microsoft that makes development of line of business (LOB) apps really easy. The team at Microsoft often talk about citizen developers – i.e. people who are not full time developers, but are the “IT guy” in the department or company that need to put together a great looking solution. The team also talk about no-code solutions – where you can build great systems without code.
 Both statements from the team are true and false at the same time. Sure your accountant can build a CRM system with no code in Lightswitch, but Lightswitches true value is that it is a professional development tool, and in reality unless it is a really simple solution you will need a touch of code.
Both statements from the team are true and false at the same time. Sure your accountant can build a CRM system with no code in Lightswitch, but Lightswitches true value is that it is a professional development tool, and in reality unless it is a really simple solution you will need a touch of code.
What is great is that Lightswitch allows the citizen developer to write a system that can be matured by professional developers later on – it’s power is that it does not lock you into being too simple or too complex a development system.
For me the value proposition is that you get REAL rapid development, that citizen developers can put together and extend solutions that are well architected and that when the need is there a professional developer can extend that solution and hand it back over to the citizen developer – it is the circle of Lightswitch.
Architecture
When you craft a (avoiding the development term here on purpose) Lightswitch create a multi-tier architecture, that is either two tier (client & database) or three tier (client, server & database). Two tier is really three tier but the server & client are just one package.
The database can be any support by Lightswitch, the middle tier is OData and the front end is Silverlight. The choice of front end has recently hurt Lightswitch because Silverlight is dying. However if you step back for a second and think about it Lightswitch provides the easiest and fastest way to build a complete (and I mean complete, authentication, methods, proper designed) OData solution… you could always ignore the client portion and build on top of the OData server.
Making a HTML Client
The HTML client mode for Lightswitch is a recently announced new feature that allows you to build a client that runs in a browser, and not just Internet Explorer on Windows (Dynamics CRM I am looking at your shameful behaviour) but pretty much any browser, say on an iPad:

This is possible because of two things, the OData server which allows really any technology to connect to it, and the second piece of the Lightswitch system the LSML file.
I hope you have never heard of the LSML file, as it is not a nice place to go to – it is a MASSIVE (even simple demo’s I build are thousands of lines) XML file that stores ALL of the Lightswitch system in a “Lightswitch domain language”. This enables the team to take that information, parse it and produce output based on it. So the concept of producing a parser that creates HTML rather than Silverlight is really simple… just build the parser.
What do we know about this HTML client so far?
It is early days, in fact there are no bits available yet, but we do know some things from the demo’s and screen shots that are available.
- Multiple themes will be supported (their is a dark & a light at least) – thanks to the jQuery Mobile that powers it.
- It is a separate client – so you will have a Silverlight experience and then also have the HTML experience added in.
- It follows the true Lightswitch model of being easy to build with no code, but if you need that little extra, the JavaScript can be edited.




The Important Two Issues
To wrap this up it is a very exciting point in time for the Lightswitch world with so much happening that I think it is important to take a step back and find a few key aspects about this amazing feature that will help position it. There are two that really stand out to me from all the announcements:
Separate Client
This is not a Silverlight to HTML generator – it is separate. This means that awesome Silverlight chart you use today will not magically work in the HTML client. This has both advantages and disadvantages, but if you think about the dying of Silverlight I am very glad that they have a whole new growth path.
It also allows for the real scenario of supporting a rich experience in Silverlight in a company (where we control all the machines and know we can run Silverlight for a long time still) and having a mobile or companion experience in HTML for those people on the road. Sure they do not get the great sales forecast chart but they can still capture their sales on their iPad.
Web Developers
A recent did an survey of app developers looked at what they are building today, what they were building and what they intend to build in the future (future = one year in this survey). Interestingly there are only TWO platforms that are getting growth in the future? HTML & Windows Phone. Android, iPhone and many others are all expected to decline.
If you think about those numbers and add in the MASSIVE investments in HTML development that are in Windows 8, it should not surprise you that web development is a MAJOR area in the future of all developers. It also means that web developers can start to have way more opportunities in the market outside of building websites & portals, and that is very exciting as that little garage web designer company today could be a major line of business developer in a few years.
Windows 8 Boot Camp: Johannesburg 24 May
 Yesterday Rudi Grobler & I had awesome fun with a full room of amazing people who took time off work to attend a full day of free Windows 8 training. The audience was amazing, breaking a lot of my expectations of how audiences react at free events, which really honoured Rudi & I to have most people stay to the very end of the day.
Yesterday Rudi Grobler & I had awesome fun with a full room of amazing people who took time off work to attend a full day of free Windows 8 training. The audience was amazing, breaking a lot of my expectations of how audiences react at free events, which really honoured Rudi & I to have most people stay to the very end of the day.

For those people who attended the training, or those who didn’t but want the content too:
- You can get the slides: http://bit.ly/win8-slides
- You can get videos from Build on the topics we discussed: http://bit.ly/win8-videos
- The demo’s I built are available to download from below.
.NET 4.5 Baby Steps, Part 8: AppDomain wide culture settings
Introduction
Culture settings in .NET are a very important but often ignored part of development, they define how numbers, dates and currencies are displayed and parsed and you application can easily break when it is exposed to a new culture.
In .NET 4, we could do three things:
- Ignore it
- Set it manually everywhere
- If we were using threads, we could set the thread culture.
So lets see how that works:
// uses the system settings
Console.WriteLine(string.Format("1) {0:C}", 182.23));
// uses the provided culture
Console.WriteLine(string.Format(CultureInfo.InvariantCulture, "2) {0:C}", 182.23));
// spin up a thread - uses system settings
new Thread(() =>
{
Console.WriteLine(string.Format("3) {0:C}", 182.23));
}).Start();
// spin up a thread - uses thread settings
var t = new Thread(() =>
{
Console.WriteLine(string.Format("4) {0:C}", 182.23));
});
t.CurrentCulture = new CultureInfo("en-us");
t.Start();
Console.ReadLine();
![CropperCapture[2]](https://www.sadev.co.za/files/CropperCapture2_2.gif "CropperCapture[2]")
You can see in the capture above lines 1 & 3 use the South African culture settings it gets from the operating system. What if I want to force say an American culture globally? There was no way before .NET 4.5 to do that.
What .NET 4.5 adds?
By merely adding one line to the top of the project, all threads, including the one we are in get the same culture:
CultureInfo.DefaultThreadCurrentCulture = new CultureInfo("en-us");
![CropperCapture[1]](https://www.sadev.co.za/files/CropperCapture1_6.gif "CropperCapture[1]")
.NET 4.5 Baby Steps, Part 7: Regular Expression Timeouts
Introduction
While the regular expression passing in .NET is damn fast, there are times where it can take too long for your needs. Until now there hasn’t been much you can do but wait. In .NET 4.5 we get the ability to timeout regular expressions if they took too long.
Problem
So lets look at a really silly example to start off with, checking a string fifty million characters (where only one is different) against regular expression which is looking for fifty million letters. As I said it is silly, but to get a truly slow reg ex is pretty hard.
static Regex match = new Regex(@"\w{50000000}", RegexOptions.None);
static void Main(string[] args)
{
var sw = Stopwatch.StartNew();
Console.WriteLine(match.IsMatch(String.Empty.PadRight(49999999, 'a') + "!"));
sw.Stop();
Console.WriteLine(sw.Elapsed);
Console.ReadLine();
}
This 13.5secs on my machine!
Solution
 All we need to do to take advantage of the new timeouts is modify the constructor of the Regex, by adding a third parameter.
All we need to do to take advantage of the new timeouts is modify the constructor of the Regex, by adding a third parameter.
static Regex match = new Regex(@"\w{50 000 000}", RegexOptions.None, TimeSpan.FromSeconds(5));
Now after five seconds a RegexMatchTimeoutException is raised.
.NET 4.5 Baby Steps, Part 5: Some more interesting blocks
Introduction
We have seen the IDataFlowBlock, in three different implementations and now we will look at a few more.
BroadcastBlock<T>
In the BatchBlock we saw that if you had multiple subscribers, messages are delivered to subscribers in a round robin way, but what about if you want to send the same message to all providers? The solution is the BoardcastBlock<T>.
static BroadcastBlock<string> pubSub = new BroadcastBlock<string>(s =>
{
return s + " relayed from publisher";
});
static async void Process()
{
var message = await pubSub.ReceiveAsync();
Console.WriteLine(message);
}
static void Main(string[] args)
{
// setup 5 subscribers
for (int i = 0; i < 5; i++)
{
Process();
}
pubSub.Post(DateTime.Now.ToLongTimeString());
Console.ReadLine();
}
![CropperCapture[1]](https://www.sadev.co.za/files/CropperCapture1_4.gif "CropperCapture[1]")
TransformBlock<TInput,TOutput>
The next interesting block is the transform block which works similar to the action block, except that the input and output can be different types and so we can transform the data internally.
static TransformBlock<int, string> pubSub = new TransformBlock<int, string>(i =>
{
return string.Format("we got: {0}", i);
});
static async void Process()
{
while (true)
{
var message = await pubSub.ReceiveAsync();
Console.WriteLine(message);
}
}
static void Main(string[] args)
{
Process();
for (int i = 0; i < 10; i++)
{
pubSub.Post(i);
Thread.Sleep(1000);
}
Console.ReadLine();
}
![CropperCapture[1]](https://www.sadev.co.za/files/CropperCapture1_5.gif "CropperCapture[1]")