Temporal API
Dates in JavaScript are terrible. We all know this, but they made big strides for it to not suck anymore.
So what do we get. No more weird constructor passing numbers around. Like you want now?
Temporal.Now
That returns a proper prototypal object. Not nonsense... and then everything gets easier. I am not going to explain these, you will just know how they work from reading - it is that nice
Temporal.Now.plainDateISO()
or how about
Temporal.Now.add({days: 1})
or
Temporal.Now.add({days: 1}).subtract({years:2})
Resources
- Great blog post which goes into way more detail
- Can I Use for your browser checks
- Deno supports it as of yesterday (of course, they are amazing) ... no word on node, but you could polyfill
Should you have an AGENTS.md?
Small paper on the usefulness of AGENTS.md files: https://arxiv.org/abs/2602.11988
Findings boil down to
- It costs more to have them - makes perfect sense, since we are putting more into context
- Human curated versions of AGENTS.md outperform auto generated - again, makes sense. The AI can't always know what is useful, it is just summarising and guessing.
- The paper tested only solving tasks and results vary based on model, but seldom is there a big swing either way for it being good or bad - this is kinda surprising to me.
- Testing is improved by having AGENTS.md - makes sense, we're telling the agent what to do each time. AGENTS.md is augmenting our prompt
- Not in this paper, but a prior worked cited in this paper tested security and that saw improvements from AGENTS.md again - makes sense, it is augmented the prompt with the security things
Ultimately, my takeaway is that AGENTS.md is not magic (no one should be surprised by that) - all the AGENTS.md is doing is just augmenting your prompt with more info. More info costs money with AIs, and more info can help or hinder if it is good or bad info. Like with anything you use, know how the tool works to get the best results and do not blindly trust AIs (even /init is an AI)
Where do I land after reading this? Keep it - not because your individual LLM use is better or worse, but as a team you commit the AGENT.md to your repo and your teams experience with AI tools is more consistent.
Also, I am way too old and forget things, so having a AGENTS.md with things I should tell the agent... rather the individual prompt costs more than I have to run the same thing 3 times and pay a lot more in totality because I forgot something.
OSTicket Spam Block
Today launching a free plugin for OSTicket, Spam Block which brings advanced anti-spam detection right into OSTicket; it also makes cleaning up spam a one click option!
It is launching on Peerlist so please upvote it there and grab the plugin from GitHub
Screenshots
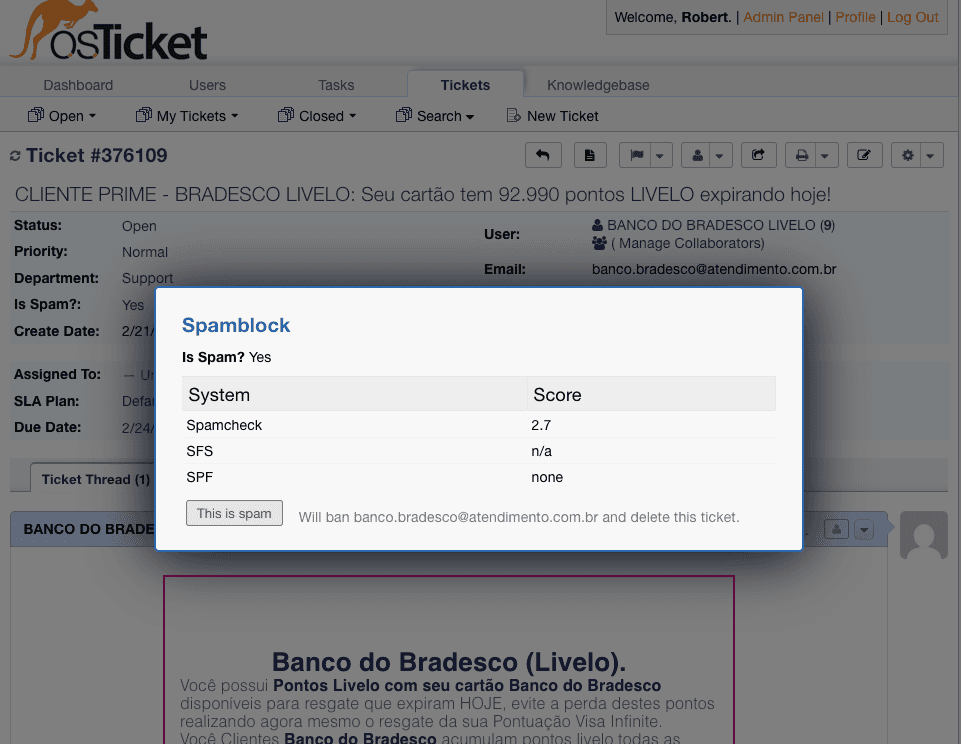
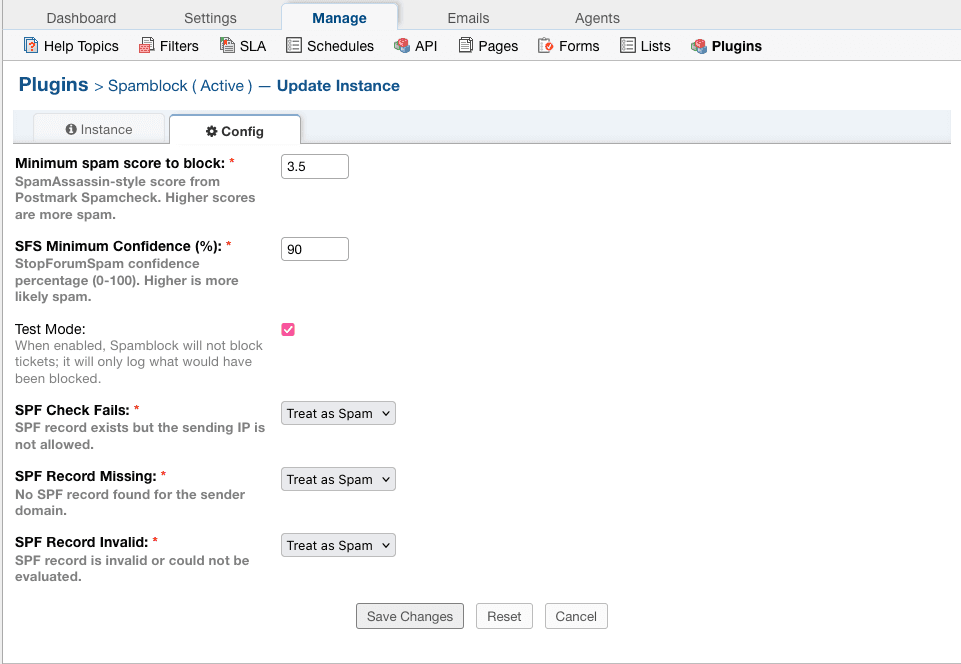
Deno!
Last night at the DeveloperUG, I spoke on Deno - an amazing runtime for TS & JS... but a lot more than that, you can see the whole list below. There is A TON in this talk if you never use the Deno runtime and stay with Node.js
The video is available on YouTube!
The slides are available here
And the code is up on GitHub.
Unfortunately, I had a demo fail at the end 🙁 but I have fixed it since it now compiles you can play with it at https://deno-demo.goodname.deno.net/ (I'll leave it up for a while but likely turn it off in the future).
In terms of the tools I showed off
Java Sealed Classes are a powerful feature and a subpar design 😜
When I was a youngling learning to code Delphi on the hard knock streets of Joburg... one thing was made very clear by the compiler and teachers were that circular dependencies are wrong... just wrong. No code will compile. I appreciate we are about 800 years from that part and tech has moved on, so it can sort of circular dependencies, but to me, it still feels like a bad design decision.
Which brings me to the Java permits keyword (also known as Sealed Interfaces), this feature allows one to create an interface and "assign" classes to it and basically get a Union type like TypeScript has; example code (note this is an empty interface - but doesn't have to be)
sealed interface Animal permits Dog, Cat {}
Now I can use Animal in my code and do a type check if it is a Dog or Cat and things just work. This also means the shape of Dog and Cat do not need to match each other (again, a Union type)... coolness. Again an example:
void speak(Animal animal) {
switch (animal) {
case Dog dog -> dog.bark();
case Cat cat -> cat.meow();
}
}
Here is the wild part for me, all the classes "joined" in this interface must also extend that interface... So Dog is an Animal, Cat is an Animal and Animal is both Cat and Dog. Example:
final class Dog extends Animal {
public String bark() { ... }
}
or
final class Cat extends Animal {
public String meow() { ... }
}
This means Animal needs to know what Cat & Dog are first, to set itself up, but, each of those classes need to know what Animal is first so that they can use it... it is a circular dependency by design. It seems like a bad - it works... just feels bad. I likely would've not had them extend the interface if it was my call. There is a perk to this though, you can force some shared shape in the interface
sealed interface Animal permits Dog, Cat {
boolean isTailWagging;
and then you end up with both classed needing to implement it, à la
final class Dog extends Animal {
public String bark() { ... }
public boolean isTailWagging() {...}
}
or
final class Cat extends Animal {
public String meow() { ... }
public boolean isTailWagging() {...}
}
and then we use that without a type check
void speak(Animal animal) {
if (!animal.isTailWagging()) {
// animal is unhappy so will make a noise
switch (animal) {
case Dog dog -> dog.bark();
case Cat cat -> cat.meow();
}
}
}
Though in my fictional design, one would just have two interfaces - one for the shared shape and one for the union... Anyway, I hope this little tangent into this was interesting, definitely good to see Java getting this sort of functionality (though it did get a while back to be fair), just need to see people using it now!
Why AI Centaurs need Git excludesFile aka why global .gitignore files are useful

Before we dive into the problem, let's set the stage for all the terms which maybe new to someone.
AI Centaur
Cory Doctorow describes Centaurs as
The idea of "centaurs" comes from automation theorists: it describes a system where a human and a machine collaborate to do more than either one could do on their own
I have recently heard this also referred to as an "AI Native", no doubt a play on "Digital Native" - but Centaurs are a better term in isolation and paired with Reverse-Centaur (see the link above for this is).
AGENTS files
So you may work with a centaur, or you may be one yourself - and if you are in that situation, you have seen the increasing AGENTS.md format slowly creeping up into a variety of your code bases. Some tools have different filenames, like Warp (which I highly recommend) uses a `WARP.md, but I am going to call them AGENTS files for this post.
A key detail on AGENTS files though is while there is a standard name, there is no standard for the content - just recommendations that your favourite AI agent/tool should use.
Problem
In theory, teams could commit their AGENTS file to the repo, and everyone in the team benefits from a single file. However, this seems to fail in 2 ways
- Most teams I have worked with do not have a standard AI tool plan and each developer is using their own favourite (some maybe not even using a tool) - this does mean each tool will want to tweak this differently or could hallucinate in odd ways getting context it does not expect or understand. In theory this should not be an issue, especially if you handcraft your AGENTS file - but theory and practise don't always align... especially with LLMs.
- In some cases, the different team members will want the AI agent they work with to work in a way that is slightly different from the rest of the team. Warp handles this nicely with Rules, but many tools don't - and now you have each team member either compromising or having battles on whose file is correct.
In these situations, the outcome is often not committing the AGENTS file and when one has a lot of code basis to flip through, this can lead to situations where one forgets and accidentally commits it, or you need to update every .gitignore all the time.
Recently though, I found core.excludesFile which is a setting in Git, which allows one to set a specific file to use inconjuction with the standard .gitignore in your project. Why this is useful is one can set this to point to a file in their home directory and set the global config for Git... which means every Git project will use that and this will let you or an AI Centaur you know put the AGENTS file in say ~/.config/.gitIgnore and then use the command git config --global core.excludesFile ~/.config/.gitIgnoreto set the file and problem solved!
Maybe you don't need the config?
While writing this up, I learnt you don't even need to set this as there is already a default value of $XDG_CONFIG_HOME/git/ignore set and if (like I think many people) have not set the XDG_CONFIG_HOME environment variable then it falls back to $HOME/.config/git/ignore.
Bonus trick
Also from the documentation, I learnt another trick
Patterns which are specific to a particular repository but which do not need to be shared with other related repositories (e.g., auxiliary files that live inside the repository but are specific to one user’s workflow) should go into the
$GIT_DIR/info/excludefile.
$GIT_DIR is the .git folder in the root of your project (normally - Git allows you to customise everything)
AWS Community Day - South Africa
![]()
What an amazing day! For the first time in South African history, we had an AWS Community Day, all thanks to the hard work of Hennie Francis and the team working with him. The organisation, swag, and content were all next-level. For a first-time event, it was stellar.
I skipped all the talks before lunch because I was having such a great time networking with the sponsors and catching up with friends. Before I knew it, it was lunchtime, followed by Dale Nunns doing his famous Duck Hunt talk (you can watch it on YouTube. Dale was amazing, as always.

The next talk I saw was from a new speaker to me, Louise Schmidtgen. She did my favourite type of talk: an honest review of a real-world failure, what was learned, and how they would avoid it in the future. Will absolutely be at her talks in future.

The final talk of the day was Mark Birch's. I had zero interest in seeing this talk from the title, "Community as Code: Engineering Human Infrastructure," especially since, like most attendees, I hadn't even read the description. But, as I've said before, conferences are a serendipity gold mineand this is yet another example of it; but not the last one of the day. For me, this talk felt like it was designed perfectly for me. I was wowed and definitely need to get his book - Community in a Box.

Following the day, I got an invitation to the speakers' dinner, and again, I just ended up in the right seat (thanks serendipity) for an amazing night of discussion and inspiration. I got to hear from Jared Naude, Lindelani Mbatha, Roberto Arico, and Liza Cullis. I am still in awe of their skills and so grateful for them sharing their wisdom and stories with me.
It was not a perfect day, unfortunately. The venue had some rather short-sighted restrictions on movement and taking photos, which is why the images in my post are cartoons I "drew myself" and totally not from photos I sneakily took and an AI changed 🙄
The venue also extended lunch without asking the organisers, which led to the last time slot of the day being cancelled. I appreciate that the venue staff were trying their best, but decisions like that need to be made by the organisers, not the venue. This meant that Candice Grobler, whose talks always blows me away, didn't get to do her talk - a big disappointment for me.

I hope this is a lesson for the venue to improve, because their reputation is in bad shape right now.
It was amazing to see how Hennie and the team coped with the challenges; they truly did an amazing job despite the venue. I cannot wait for the 2026 event! I will be getting tickets as soon as they come out!
The serendipity of the conference
My experience at yesterday's DataConf, a fantastic event organised by two people I adore, Candice Mesk and Mercia Malan, perfectly illustrates this. My day began as usual: catching up with friends and desperately trying to convince the Bootlegger coffee people to open early just for me. ☕
I had my first serendipitous moment before the day even began. Quinn Grace asked me what I thought comes after AI. The conversation and the ideas that came from that discussion were awesome, and I am still thinking on it as I write this.
Another moment of serendipity happened after lunch. I was unsure which talk to attend, so I simply stayed in the main room without even really knowing what the talk was about. It turned out to be the most practical talk of the day for me: "How to craft teams of exceptional analysts" by Lisema Matsietsi. The title alone screamed that this was NOT a talk for me, and like many attendees, I never read the description, so I was flying blind. This was pure serendipity. The talk was entirely leadership-focused and helped illuminate parts of team dynamics I hadn't deeply understood. I'm so glad it was at the event; it just goes to show how you can end up in the right room at the right time---despite yourself.
The Learning Was in the Talks
I initially thought I'd written enough on the topic, but Duncan Dudley told me my posts were too short. I also thought I'd steal a page from Dale Nunns wonderful post on the event (he even has photos... I am way too lazy for that), so here are some of the actual learnings that happened for me.
I had the pleasure of watching certified genius (certified by me - still counts) Michael Johnson talk about data engineering. As the resident "not data" guy, his talk was incredibly useful, giving a wonderful look at the history of the field and why we are where we are. It really helped me understand the landscape better.
This was followed by Pippa Hillebrand who has the genius and laser focus of your favourite super villain, but without the desire to take over the world. Her talk on AI privacy was so powerful, focusing not on how we build AIs, but on how we run them and the risks involved.
Pippa's talk was a perfect lead-in for the funniest and most genuine speaker of the day, Georgina Armstrong. Her talk on recommender systems was genius. I wish DataConf had recorded these talks because hers is a must-see, if for no other reason than so my partner didn't have to listen to me go over every detail when I got home.
I've already mentioned Lisema's talk, so I'll move on to Marijn Hazelbag, PhD talk on digital twins with cellphones and fibre networks. While it was entirely pointless to my work, it was SO interesting (also extra points for the only live demo of the day, which helped captivate me more). It opened a door to a world I didn't know existed. I have no idea if I'll ever need that knowledge, but serendipity may have a plan for it.
The talks of the day concluded with Carike Blignaut-Staden, who gave a must-see talk for any team building a dashboard. I've been guilty of doing all the things she said you shouldn't do, which is a great place to learn from because it's all about improving from there.
What a wonderful day. I hope this encourages you to try a conference. And when you do, maybe skip a talk to discuss the future of work or go to a talk you wouldn't normally have chosen. It just might lead to an even better experience.
Originally posted to my LinkedIn but thought would share here too for those who don't follow me there: https://www.linkedin.com/pulse/serendipity-conference-robert-maclean-342pf/?trackingId=shsYleAzXj22zxAHwx6J%2BQ%3D%3D
The Git LFS Problem with SSH Profiles
Like anyone with a brain, I want mine to be as empty as possible of important things so I can fill it with memes and TV quotes. To help that process, I put my passwords into a password manager—mostly for security, but also for convenience.
1Password, like others, supports running an SSH agent, which is amazing when you have multiple accounts on GitHub and GitLab that all need SSH. It provides great portability, and for most things, it just works.
This does mean having something like this in my ssh config file so I can reference each account with a different name:
Host personalgh
HostName github.com
User git
IdentityFile ~/.ssh/rmaclean_github.pub
IdentitiesOnly yes
Host clientAgh
HostName github.com
User git
IdentityFile ~/.ssh/clientA_github.pub
IdentitiesOnly yes
Then, when I git clone, I don't use [email protected]:rmaclean/developmentEnvironment.git, instead, I use personalgh:rmaclean/developmentEnvironment.git. This instructs Git to use the specific profile in the SSH config.
This works great, except if you use Git LFS (Large File Storage). Over the last 14 months, I’ve used LFS a lot since one of my clients is a game developer, and LFS is essential for all the binary assets. Since LFS uses a separate process, it makes assumptions about the hostname and thinks the SSH profile name is the hostname. And you get an error like this:
Cloning into 'demo'...
remote: Enumerating objects: 4108, done.
remote: Counting objects: 100% (234/234), done.
remote: Compressing objects: 100% (127/127), done.
remote: Total 4108 (delta 140), reused 149 (delta 103), pack-reused 3874 (from 3)
Receiving objects: 100% (4108/4108), 1.62 MiB | 1.46 MiB/s, done.
Resolving deltas: 100% (2524/2524), done.
Downloading public/assets/audio/music/Arcade_LoopNew.mp3 (2.4 MB)
Error downloading object: public/assets/audio/music/Arcade_LoopNew.mp3 (425014c): Smudge error: Error downloading public/assets/audio/music/Arcade_LoopNew.mp3 (425014c3f342e099e5c041b875d440e9547ef4fb2a725d41bb81992ad9f37ddd): batch request: ssh: Could not resolve hostname clientA: nodename nor servname provided, or not known: exit status 255
Errors logged to '/private/tmp/demo/.git/lfs/logs/20250826T090610.648994.log'.
Use `git lfs logs last` to view the log.
error: external filter 'git-lfs filter-process' failed
fatal: public/assets/audio/music/Arcade_LoopNew.mp3: smudge filter lfs failed
warning: Clone succeeded, but checkout failed.
You can inspect what was checked out with 'git status'
and retry with 'git restore --source=HEAD :/'
To fix this, you must use the standard [email protected]: host structure. But since you also need to pass in the correct SSH key, you can do that with a temp config setting: core.sshCommand.
When cloning, you can specify the command directly:
git -c core.sshCommand="ssh -i ~/.ssh/clientA_github.pub" clone [email protected]:client/demo.git
After successfully cloning the repository, any subsequent pushes or pulls will still fail. This is because the repository is not yet configured to use the right key. The git clone command simply added a parameter for that single operation—it didn't change the repository’s configuration.
To fix this, you need to set the configuration correctly after the clone. Switch into the cloned folder and run this command:
git config core.sshCommand "ssh -i ~/.ssh/clientA_github.pub"
This command sets the core.sshCommand for the repository, ensuring that it always uses the correct key. Now it will just work.
The Case of the Dotty Environment Variables
This post is for that one other person who's losing their mind over a bizarre issue: lowercase environment variables with dots in their names not showing up in one environment, when it works elsewhere.
The client's request was simple: configure all environment variables with a naming convention like my.app.variable. Everything I knew suggested this was impossible—environment variables typically follow a UPPERCASE_SNAKE_CASE convention and don't play well with special characters like dots. Yet, in their environment it works.
The Investigation
To get to the bottom of this, I created a minimal, reproducible example using a simple Java application that reads an environment with the k8s and dockerfile need to run it. I hosted the code on GitHub for anyone to see and confirm: it worked. I could evensh into the container and confirm the variables were present and correctly formatted using the env command.
The puzzle deepened. The environment variables were definitely there and readable, so why couldn't my real application see them?
The Unexpected Culprit
After a lot of debugging, I finally found the problem: the Docker base image.
In the client's working environment and my local test (by coincidence), were running on eclipse-temurin:21-jre-alpine. The actual project code, however, was using eclipse-temurin:21-jre.
The difference seems subtle, but it was critical. The alpine version, being a minimal Linux distribution, likely handles environment variable parsing differently or has a different shell configuration (via the entry point being bash) that allows these non-standard variable names to be passed and read correctly. The standard image, based on a different underlying OS (likely Debian or similar), does not.