Learning Kotlin: The awesome that is the backtick
- This is the 14th post in a multi-part series.
If you want to read more, see our series index
The backtick in Kotlin is meant to allow Kotlin to use keywords or, since Kotlin is meant to interop with Java, allow Kotlin to call Java functions that might conflict with Kotlin; for example, this won't work
val class = "school"
println(class)
If we wrap class in backticks (as it is a keyword) then it works just fine:
val \`class\` = "school"
println(\`class\`)
This is nice... however it can be used for function names too, for example with tests we might use underscores to make the name verbose:
fun should_return_true_for_values_of_one() {
however...
fun \`should return true for values of one\`() {
Yes! That is a function name with REAL SPACES in it! AWESOME!
Learning Kotlin: return when
- This is the 13th post in a multipart series.
If you want to read more, see our series index
Continuing our break from the Koans today and going to look at another cool trick I learnt using Kotlin this week and focusing on the when keyword we learnt about previously;
Let's start with a simple function to return the text for a value using when:
fun step1(number: Int):String {
var result = "";
when (number) {
0 -> result = "Zero"
1 -> result = "One"
2 -> result = "Two"
}
return result;
}
The next evolution is we can avoid creating a variable and returning directly (this is something I would do often in .NET)
fun step2(number: Int):String {
when (number) {
0 -> return "Zero"
1 -> return "One"
2 -> return "Two"
}
return ""
}
And now we get to the cool part, we can just return the when!
fun step3(number: Int):String {
return when (number) {
0 -> "Zero"
1 -> "One"
2 -> "Two"
else -> ""
}
}
Yup, the when can return a value which means we can also do one final trick:
fun step4(number: Int):String = when (number) {
0 -> "Zero"
1 -> "One"
2 -> "Two"
else -> ""
}
It is so cool that your logic can just return from a condition, and it works with if statements too and even with the Elvis operator we learnt yesterday:
fun ifDemo3(name:String?) = name ?: "Mysterious Stranger"
Learning Kotlin: Kotlin's Elvis Operator
- This is the 12th post in a multipart series.
If you want to read more, see our series index
We are going to take a short break from the Koans and look at a cool trick I learnt today. Previously, we learnt about the safe null operator but that only helps when calling functions or properties of objects...
fun ifDemo1(name:String?) {
val displayName = if (name != null) name else "Mysterious Stranger"
println("HI ${displayName}")
}
In the above example, we have the name String which could be null but safe null operator (this needs a better name) can't help here... so let us look at what Kotlin calls the Elvis operator ?: and what it gives us:
fun ifDemo2(name:String?) {
val displayName = name ?: "Mysterious Stranger"
println("YO ${displayName}")
}
This is really cool and reminds me of SQL COALESCE where it lets you test the first value and if it is not null, it returns the first value, else it returns the second value.
SFTPK: Heap
This post is one in a series of stuff formally trained programmers know – the rest of the series can be found in the series index.
Continuing on with more tree-based data structures, we get to the heap. If we look back at the BST and Red/Black those trees ended up with the most average/middle value at the root node so that nodes which were smaller were on the left and larger nodes were on the right, the heap changes that.
There are actually two heaps, a minimum and maximum value heap, but there are very similar. The key aspects to know about either heap are
- It is a binary tree. This is important for insertion and deletion and ensures the depth of the tree doesn't grow out too far from the root node.
- In a minimum heap, the root node is the SMALLEST value in the tree.
- In a minimum heap, any node should be smaller than all of its' children
- In a maximum heap, the root node is the LARGEST value in the tree
- In a maximum heap, any node should be larger than all of its children
The advantage of a heap is as an implementation of a Queue where you can control the order items appear in the queue rather than just relying on insertion order.
Let's have a look at what these will look like when we have the following dataset: 45, 42, 56, 78, 99, 30
| Step | Minimum Heap | Maximum Heap | ||
|---|---|---|---|---|
| 1 | We add 45 as the root node | We add 45 as the root node | ||
| 2 | We add 42 as the first child, but it is smaller, so we will swap it with the root node |  {width=100} {width=100}  {width=100} {width=100} |
We add 42 add as the first child node |  {width=100} {width=100} |
| 3 | We add 56 as the second child node |  {width=100} {width=100} |
We add 56 as the second child node; it is larger than its parent so we swap them. |  {width=100} {width=100}  {width=100} {width=100} |
| 4 | We add 78 as a child of 45 |  {width=100} {width=100} |
We add 78 as a child of 42, though it is larger so it must be swapped. 78 is now a child of 56, which still wrong so we need to swap them too. |  {width=100} {width=100}  {width=100} {width=100}  {width=100} {width=100} |
| 5 | We add 99 as a child of 45 |  {width=100} {width=100} |
We add 99 as a child of 56. 99 is larger, so we then swap 99 and 56. 99 is still larger than 78, so we need to swap those nodes too |  {width=100} {width=100} 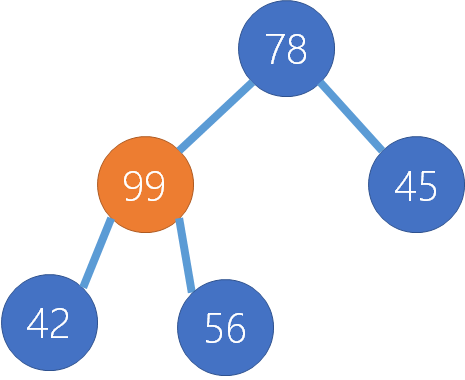 {width=100} {width=100}  {width=100} {width=100} |
| 6 | Next we add 30 under 56. It is smaller than 56 so it must be swapped. Once swapped, its parent 42 is also larger so they need to swapped too. |  {width=100} {width=100}  {width=100} {width=100}  {width=100} {width=100} |
Last we add 30 to under 45. |  {width=100} {width=100} |
Implementations
Java has a built-in implementation with the PriorityQueue and, unfortunately, .NET and JavaScript lacks an out of the box option.
Learning Kotlin: Object Expressions and SAM Conversions
- Code for the first Koan can be found here.
- Code for the second Koan can be found here.
- This is the 11th post in a multipart series.
If you want to read more, see our series index
For the 11th post, we get something new to an old C# person - Object Expressions!
Object Expressions are very similar to Anonymous Classes in Java where you can declare a class inline rather than entirely separately in its own file.
In the first Koan we need to implement Comparator<Int> inline:
fun task10(): List {
val arrayList = arrayListOf(1, 5, 2)
Collections.sort(arrayList, object : Comparator {
override fun compare(o1:Int, o2:Int):Int {
return o2 - o1;
}
})
return arrayList
}
You can see on line 21, we define the new object with the object keyword and then use : Comparator<Int> to state it implements that interface. The Comparator has a single function which needs to be implemented which we do on line 22.
The second Koan takes this further and states if there is a single method in an abstract class or interface then we can use SAM, or Single Abstract Method, to avoid needing the class at all as we just need to implement the single function. To achieve this with the Koan, we use an anonymous function that handles the compare function of the Comparator:
fun task11(): List {
val arrayList = arrayListOf(1, 5, 2)
Collections.sort(arrayList, { x, y -> y - x})
return arrayList
}
and lastly, if we look back to previous post we can use the extension method to simply it further:
fun task12(): List {
return arrayListOf(1, 5, 2).sortedDescending()
}
---
These Koans have given me more thoughts about the language than probably any previous Koans:
- Why do classes which implement an interface use override?
In C#, when you implement an interface you do not need to state that you are not overriding the functions (see this example). In C# only state that your are overriding when you inherit from a function and you actually override a function. The reason is that an interface in Kotlin is closer to an abstract class than in C#, to the point it can have functionality - yup, interfaces can have functions and logic! - So why does Kotlin have interfaces and abstract classes?
The key difference is an abstract class can have state while the logic in an interface needs to be stateless! - Why bother having SAM?
As I was working on the Koan, I was delighted by the SAM syntax... and then I wondered why I needed this at all? Why isCollections.sorttaking a class as the second parameter? Why not just pass in a function, since that is all that is actually needed? Both C# and Kotlin supports passing functions so this is possible... but something I never knew about Java is that it doesn't support passing functions! You have to use Callable, a class, to pass functions.
Learning Kotlin: Extension Functions and Extensions On Collections
- Code for the first Koan can be found here.
- Code for the second Koan can be found here.
- This is the 10th post in a multipart series.
If you want to read more, see our series index
This post is the first to cover multiple Koans in a single post.
The 10th in our series is very simple coming from C# because Extension Functions in Kotlin are identical as Extension Methods in C#, though they are much cleaner in their implementation.
In their example for the Koan we add a lastChar and lastChar1 function to the String class.
fun String.lastChar() = this.get(this.length - 1)
// 'this' refers to the receiver (String) and can be omitted
fun String.lastChar1() = get(length - 1)
For the Koan itself, we need to an r function to Int and Pair<int, int> which returns an instance of RationalNumber, which we do as follows:
fun Int.r(): RationalNumber = RationalNumber(this, 1)
fun Pair.r(): RationalNumber = RationalNumber(first, second)
An additional learning on this, was the Pair<A, B> class which is similar to the Tuple class from C#.
When we get into the second Koan, we get exposed to some of the built-in extension's functions in Kotlin which ship out of the box; in this case, we use sortedDescending extension method with the Java collection. It is a great example of mixing Java and Kotlin too:
fun task12(): List {
return arrayListOf(1, 5, 2).sortedDescending()
}
Learning Kotlin: Smart Casts
- Code for this Koan can be found here.
- This is the 9th post in a multipart series.
If you want to read more, see our series index
The goal of this Koan is to show how smart the Kotlin compiler is; in that when you use something like the is keyword to handle type checking the compiler will then know the type later on and be able to use it intelligently.
So if we want to check types in Java we would use something like this where we would use instanceof to check the type and then cast it to the right type.
public class JavaCode8 extends JavaCode {
public int eval(Expr expr) {
if (expr instanceof Num) {
return ((Num) expr).getValue();
}
if (expr instanceof Sum) {
Sum sum = (Sum) expr;
return eval(sum.getLeft()) + eval(sum.getRight());
}
throw new IllegalArgumentException("Unknown expression");
}
}
In Kotlin we, by checking the type the compiler handles the casting for us, but before we get to that we also got to learn about the when which is the Kotlin form of the Switch keyword in C# or Java and it offers similar functionality, as shown in this example:
when (x) {
1 -> print("x == 1")
2 -> print("x == 2")
else -> { // Note the block
print("x is neither 1 nor 2")
}
}
and it supports multiple values on the same branch
when (x) {
0, 1 -> print("x == 0 or x == 1")
else -> print("otherwise")
}
Where it gets awesome, is the extra actions it supports; for example when values can be functions, not just constants:
when (x) {
parseInt(s) -> print("s encodes x")
else -> print("s does not encode x")
}
You can also use in or !in to check values in a range/collection:
when (x) {
in 1..10 -> print("x is in the range")
in validNumbers -> print("x is valid")
!in 10..20 -> print("x is outside the range")
else -> print("none of the above")
}
It really is very cool, so let us see how we use Smart Casts and when together and how it compares with the Java code above:
fun eval(e: Expr): Int =
when (e) {
is Num -> e.value
is Sum -> eval(e.left) + eval(e.right)
}
Really nice and, I think, more readable than the Java code.
Learning Kotlin: Nullable Types
- The code being referenced.
- This is the 8th post in a multipart series.
If you want to read more, see our series index
The next Koan looks at how Kotlin handles nulls, and it does it wonderfully; Null is explicitly opt-in. For example, in C# you can assign null to a string variable but in Kotlin unless you say you want to support nulls, which you do by adding a trailing question mark to the class, you cannot.
Their example in this Koan is a nice example:
fun test() {
val s: String = "this variable cannot store null references"
val q: String? = null
if (q != null) q.length // you have to check to dereference
val i: Int? = q?.length // null
val j: Int = q?.length ?: 0 // 0
}
Let us dig into the Koan, where we get given the following Java code:
public void sendMessageToClient(@Nullable Client client, @Nullable String message, @NotNull Mailer mailer) {
if (client == null || message == null) return;
PersonalInfo personalInfo = client.getPersonalInfo();
if (personalInfo == null) return;
String email = personalInfo.getEmail();
if (email == null) return;
mailer.sendMessage(email, message);
}
and we need are going to rewrite it using the Nullable language features of Kotlin, which looks like:
fun sendMessageToClient(client: Client?, message: String?, mailer: Mailer) {
val email = client?.personalInfo?.email
if (email == null || message == null) return
mailer.sendMessage(email, message)
}
The big changes from Java:
- The @NotNull attribute for
maileris no longer needed - The @Null attribute for the other parameters becomes the question mark
- We do not need to pre-check
clientbefore calling the parameter, as you can use the null safe operator?.to ensure you only check before we call the method. - Unfortunately, the null safe operator in Kotlin doesn't support calling methods on null objects as C# currently does with its Elvis operator
SFTPK: Stack & Queue
This post is one in a series of stuff formally trained programmers know – the rest of the series can be found in the series index.
In this post, we will look at two related and simple data structures, the Stack and the Queue. The stack is a structure which can be implemented with either an Array or Linked List.
An important term for understanding a stack is that it is LIFO, last-in-first-out, system; namely, the last item you add (or push or bury) is the first item you take out when you retrieve an item (or peek or unbury).
Let's have a look at what a stack would look like:

In this, we added 1, 2, 3, 4, and then 5 and when we read from the stack we read in the reverse order.
#Implementations
Next is the queue, which is very similar to the stack, except where the stack was LIFO; a queue is FIFO, first-in-first-out; so if we put in 1, 2, 3, 4, & 5 into the queue, then we would read them in the same order, i.e. 1, 2, 3, 4, 5.
Implementations
C# has a queue implementation and the JavaScript array can act as a queue, when you use unshift to add to the beginning of the array (also known as the head) and pop to remove from the end of the array (also known as the tail).
Learning Kotlin: Data Classes
- The code being referenced.
- This is the 7th post in a multipart series.
If you want to read more, see our series index
WOW! Data Classes are awesome! I really like a lot of how classes are handled in Kotlin, but Data Classes are the pinnacle of that work. The effort for this Koan is to convert this Java class to Kotlin:
package i_introduction._6_Data_Classes;
import util.JavaCode;
public class JavaCode6 extends JavaCode {
public static class Person {
private final String name;
private final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
}
and what does that look like in Kotlin?
data class Person(val name: String, val age: Int)
Yup, a single line. The data annotation adds a number of important functions (like ToString and copy). We then declare the class with a constructor which takes two parameters which both become properties.
Another important aspect I learnt with this one is that Kotlin has both a val and var keyword for variables. We have seen var already and val is for read-only variables.